The raspberry pi’s ecosystem makes it a tempting platform for building computer vision projects such as home security systems. For around $80, one can assemble a pi (with sd card, camera, case, and power) that can capture video and suppress dead scenes using motion detection – typically with motion or MotionEye. This low-effort, low-cost solution seems attractive until one considers some of its shortfalls:
- False detection events. The algorithm used to detect motion is suseptible to false positives – tree branches waving in the wind, clouds, etc. A user works around this by tweeking motion parameters (how BIG must an object be) or masking out regions (don’t look at the sky, just the road)
- Lack of high level understanding. Even in tweeking the motion parameters anything that is moving is deemed of concern. There is no way to discriminate between a moving dog and a moving person.
The net result of these flaws – which all stem from a lack of real understanding – is wasted time. At a minimum the user is annoyed. Worse they are fatigue and miss events or neglect responding entirely.
By applying current state of the art AI techniques such as object detection, facial detection/recognition, one can vastly reduce the load on the user. To do this at full frame rate one needs to add an accelerator, such as the Coral TPU.
In testing we’ve found fairly good accuracy at almost full frame rate. Although Coral claims “400 fps” of speed – this is inference, not the full cycle of loading the image, running inference, and then examining the results. In real-world testing we found the full-cycle results closer to 15fps. This is still significantly better than the 2-3 fps one obtains by running in software.
In terms of scalability, running inference on the pi means we can scale endlessly. The server’s job is simply to log the video and metadata (object information, motion masks, etc.).
Here’s a rough sketch of such a system:
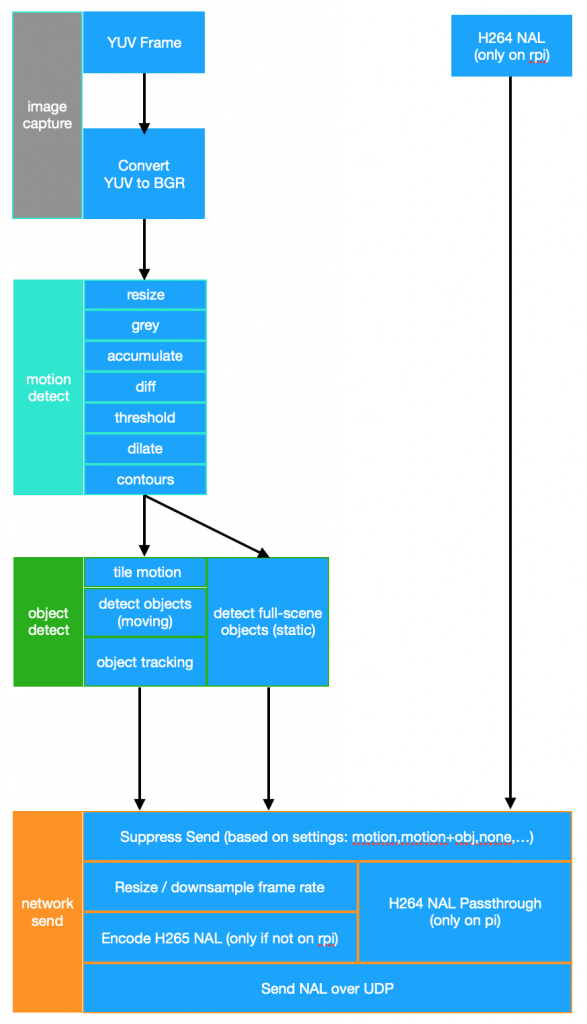
This approach is currently working successfully to provide the following, per rpi camera:
- moving / static object detection
- facial recognition
- 3d object mapping – speed / location determination
This is all done at around 75% CPU utilization on a 2GB Rpi 4B. The imagery and metadata are streamed to a central server which performs no processing other than to archive the data from the cameras and serve it to clients (connected via an app or web page).